功能发布:AIForge 模块化 AI 应用体

我们团队最近在进行 AI 应用方面的尝试,综合之前有的基础设置,更新了一个 yaklang 库:aiforge。
其中我们定义了一种 AI 应用体,取名为 aiforge,它可以通过一定的预设和编程将一些复杂的事物包装起来,完成模块化 AI 能力的工作。
我们提供两种方式编写一个 aiforge:配置文件方式和 YAK 脚本方式。其中配置文件方式在后面的版本中会通过 UI 的形式帮助用户编写。本文中主要介绍如何通过 YAK 脚本的方式编写 aiforge。
简单 AI 任务:片段文本总结
我们可以直接通过一个内置的简单 aiforge 快速上手片段文本总结:
textSnippent = cli.String("textSnippet", cli.setRequired(true), cli.setHelp("文本片段内容"))
limit = cli.Int("limit",cli.setDefault("50"),cli.setHelp("字数限制"))
cli.check()
plan = <<<plandata
```json
"@action": "plan",
"query": "-",
"main_task": "文本片段生成简洁总结",
"main_task_goal": "对用户的输入的内容进行分析和总结,提取出关键信息,并生成简洁的总结文本。",
"tasks": [
"subtask_name": "文本总结",
"subtask_goal": "分析用户输入的文本内容,提取出关键信息,并生成简洁的总结文本。"
plandata persis = <<<persistent 你是一个简单文本片段总结器,你正在总结一个文本片段。请遵循以下规则:
- 关键信息优先:保留核心事实、结论或行动项,忽略次要细节。
- 保持中立:不添加原文未明确提及的推断。
- 字数限制:不超过 [%d] 字
- 输出格式:按照下列json schema 输出: { "$schema": "http://json-schema.org/draft-07/schema#", "type": "object", "required": ["@action", "summary"], "additionalProperties": false, "properties": { "@action": { "const": "summarize", "description": "标识当前操作的具体类型" }, "summary": { "type": "string", "description": "总结的文本" } } } persistent aiforgeHandle = func(params) { summary = "" bp = aiagent.Createaiforge("fragment-summarizer", aiagent.plan(func(config){ res,err = aiagent.ExtractPlan(config, plan) if err != nil { config.EmitError("yak review plan mock failed: %s", err) return nil } return res }), aiagent.persistentPrompt(sprintf(persis, limit)), aiagent.agreeYOLO(true), aiagent.extendedActionCallback("summarize", func(config , action) { summary = action.GetString("summary") }), ) ordr,err = bp.CreateCoordinator(context.Background(),params) if err != nil { return nil } err = ordr.Run() if err != nil { return nil } return summary }
## 参数设定
对一个 AI 应用来说,如果只接受一个 query 的类 chat 输入是不够的,需要能定义和能处理结构化输入,才能像使用一个工具一样来使用 AI 应用。
`AIForge` 中可以使用 YAK 的 cli 库作为参数的定义,定义好 cli 参数可以在 Yakit 的前端生成对应的输入表单,以便用户输入。
我们以上面的片段文本总结 `aiforge` 为例,定义了下列两个参数:
- textSnippent 文本片段内容
- limit 总结限制长度
## 功能回调
在 Yaklang aiforge 的定义里,我们把 `aiforgeHandle` 作为一个魔法函数,会将 aiforge 的逻辑代码写在其中,这个函数接收一个参数,返回一个结果。
```go
aiforgeHandle = func(params) {
summary = ""
// 创建一个 aiforge 的blueprint(蓝图),可以设置与ai交互预设行为
bp = aiagent.Createaiforge("fragment-summarizer",
aiagent.plan(func(config){// 指定 ai执行任务的规划行为,让ai按照固定的任务计划执行工作
res,err = aiagent.ExtractPlan(config, plan)
if err != nil {
config.EmitError("yak review plan mock failed: %s", err)
return nil
}
return res
}),
aiagent.persistentPrompt(sprintf(persis, limit)), // 每次与ai交互都添加的提示词,可用于重要信息
aiagent.agreeYOLO(true), // 自动同意ai行为,常常用小型任务,减少人的参与
aiagent.extendedActionCallback("summarize", func(config , action) { // 定义ai的输出结果获取,从ai的输出中获取结构化的数据
summary = action.GetString("summary")
}),
)
ordr,err = bp.CreateCoordinator(context.Background(),params) // 通过蓝图创建一个执行ai任务的实体(Coordinator)
if err != nil {
return nil
}
err = ordr.Run() // 运行ai任务
if err != nil {
return nil
}
return summary // 返回结果
}
这就是一个简单的 aiforge 的实现,它完成的功能是对文本片段的总结。
长上下文任务:长文本总结
在看一个更复杂的 aiforge 之前,我们先聊聊另一个话题:长上下文任务。
真实场景中,很多问题是需要复杂决策的,这些决策往往需要贯通万字内容上下文,例如:- 医疗诊断:需综合患者数月内的检查报告、用药记录和症状变化- 司法研判:要串联案件线索、证人证词和法律条文的时间逻辑链- 商业决策:须分析市场动态、供应链数据和消费者行为的长期关联这些任务不仅要求模型记住信息,更需要建立跨段落、跨模态的语义关联,传统注意力机制在千字文本后准确率骤降,而显存消耗随文本长度呈指数级增长。那么在大模型本身限制了应用空间时,内源性解决长上下文任务遇到阻碍时,我们就思考能否通过外源性的方式来扩展记忆维护。经过我们一段时间的探索,我们使用 aiforge 的方式尝试解决这个问题。
内置的 aiforge 中就有这么一个简单验证:长文本总结。
上文有提过,aiforge 能处理结构化的输入,并产出相应的输出。那么意味着 aiforge 是可以像函数一样使用的。而内置长文本总结,就是通过代码组织调用的方式维护了一个简单的上下文记忆,使 aiforge 可以一定程度上超越 AI 本身的上下文限制。
text = cli.String("text", cli.setHelp("直接输入的长文本"))
filePath = cli.String("filePath", cli.setHelp("长文本文件"))
cli.check()
aiforgeHandle = func(params) {
ctx = context.Background()
textChan = make(chan string)
if text != "" {
textChan = str.TextReaderSplit(ctx,str.NewReader(text))
}elif filePath != "" {
textChan = str.TextReaderSplit(ctx, file.Open(filePath)~)
}else {
return
}
fragmentSummarize := func(poly) {
result, err := aiagent.Executeaiforge(
"fragment_summarizer",
{
"textSnippet": poly,
"limit": 100
}
)
if err != nil {
return ""
}
return result
}
textReducer := x.NewReducer(10, func(data) {
polyData := str.Join(data, "\n")
return fragmentSummarize(polyData)
})
for s := range textChan {
textReducer.Push(fragmentSummarize(s))
}
reduceData := str.Join(textReducer.GetData(), "\n")
result, err := aiagent.Executeaiforge(
"fragment_summarizer",
{
"textSnippet": reduceData,
"limit": 300
}
)
if err != nil {
return nil
}
return result
}
不难发现,这个长文本总结的 aiforge 是没有创建新的 forge 蓝图的,而是通过编码的方式,组织之前提过的片段总结的 aiforge 完成功能。
此 aiforge 的通过 reduce 的方式,不断对文本进行压缩,保留信息维护好较长的上下文信息,一定程度上解决长文本总结受限于 AI token 的问题。
现在,使用 forge 总结一下小说 《我的叔叔于勒》:
再长一点的小说 《羊脂球》:
效果还不错,证明可以通过代码组织以及 aiforge 内部的机制,跨越 AI 的上下文限制,完成一些长上下文的工作。
自定义编写:小说人物关系总结
上面是内置的两个 forge 的介绍,下面我们来做尝试编写一个有意思小 aiforge,来完成另一个长上下文任务:
小说人物关系总结
text = cli.String("text", cli.setHelp("直接输入的长文本"))
filePath = cli.String("filePath", cli.setHelp("长文本文件"))
cli.check()
subPlan = <<<plandata
```json
"@action": "plan",
"query": "-",
"main_task": "对文本片段进行人物关系提取",
"main_task_goal": "对文本片段进行人物关系提取,会在提取的时候同步提供一些上下文信息,比如当前的片段开始时每个人称代词的指向,以及已有的人物关系",
"tasks": [
"subtask_name": "人物关系提取",
"subtask_goal": "在输入的基础继续总结分析人物关系,输出新的人物关系,以及新的上下文信息"
plandata subPersis = <<<persistent 你是一个简单文本片段处理器,现在需要你总结一个文本片段的人物关系,以及此片段结束时一些上下文信息,比如人称代词的指向
- 关注主要关系:关注主要的人物关系,次要的人物或不重要的关系可以省略。
- 人物关系上下文: 会同步输入前文已有的人物关系,总结新的人物关系需要在之前的人物关系中增改。输入名为 "relationship"
- 代词问题:会同步输入一些片段的语境信息,里面会有当前片段开始的代词指向,可以作为总结信息的人物关系的参考依据。输入名为 "context" 。不要在总结的人物关系中出现“你我他”这类人称代词。
- 输出格式:按照下列json schema 输出: { "$schema": "http://json-schema.org/draft-07/schema#", "type": "object", "required": ["@action", "relationship","context"], "additionalProperties": false, "properties": { "@action": { "const": "process", "description": "标识当前操作的具体类型" }, "relationship": { "type": "string", "description": "更新后的人物关系" }, "context": { "type": "string", "description": "此片段结束时各个人称代词指向的人物,包括 你、我、她、他、它以及其复数形式,若没有对应的执行则不输出" } } } persistent summaizeRelationship= func(params) { relationship = "" subContext = "" bp = aiagent.CreateForge("summaize-relationship", aiagent.plan(func(config){ res,err = aiagent.ExtractPlan(config, subPlan) if err != nil { config.EmitError("yak review plan mock failed: %s", err) return nil } return res }), aiagent.persistentPrompt(subPersis), aiagent.agreeYOLO(true), aiagent.disableToolUse(), aiagent.extendedActionCallback("process", func(config , action) { relationship = action.GetString("relationship") subContext = action.GetString("context") }), aiagent.resultHandler(func(config){}) ) ordr,err = bp.CreateCoordinator(context.Background(),params) if err != nil { return nil,nil } err = ordr.Run() if err != nil { return nil,nil } return relationship,subContext } dotPlan = <<<plandata
"@action": "plan",
"query": "-",
"main_task": "对文本中表达的人物关系进行转化",
"main_task_goal": "对文本中表达的人物关系进行转化,使用dot语言表示成关系图的形式",
"tasks": [
"subtask_name": "人物关系转化",
"subtask_goal": "对文本中表达的人物关系进行转化,使用dot语言表示成关系图的形式"
plandata dotPersistent = <<<persistent 你是一个简单文本片段处理器,现在需要你将一段文本表达的人物关系使用dot语言表述出来 输出格式:按照下列json schema 输出: { "$schema": "http://json-schema.org/draft-07/schema#", "type": "object", "required": ["@action", "res"], "additionalProperties": false, "properties": { "@action": { "const": "process", "description": "标识当前操作的具体类型" }, "res": { "type": "string", "description": "表达人物关系的dot 语言" } } } persistent relationship2Dot= func(params) { dotContent := "" bp = aiagent.CreateForge("relationship2dot", aiagent.plan(func(config){ res,err = aiagent.ExtractPlan(config, dotPlan) if err != nil { config.EmitError("yak review plan mock failed: %s", err) return nil } return res }), aiagent.persistentPrompt(dotPersistent), aiagent.agreeYOLO(true), aiagent.disableToolUse(), aiagent.extendedActionCallback("process", func(config , action) { dotContent = action.GetString("res") }), aiagent.resultHandler(func(config){}) ) ordr,err = bp.CreateCoordinator(context.Background(),params) if err != nil { return nil } err = ordr.Run() if err != nil { return nil } return dotContent } forgeHandle = func(params) { ctx = context.Background() textChan = make(chan string) if text != "" { textChan = str.TextReaderSplit(ctx,str.NewReader(text)) }elif filePath != "" { textChan = str.TextReaderSplit(ctx, file.Open(filePath)~) }else { return } relationship = "" subContext = "" for s := range textChan { res,resContext = summaizeRelationship({ "content":s, "relationship": relationship, "context":subContext }) if res != "" { relationship = res } if resContext != "" { subContext = resContext } } return relationship2Dot({ "relationshipContent":relationship }) }
此 forge 大致可以分为两个部分`关系总结`和`关系图转化`。这样分配任务的原因是AI 类似于人,它对自然语言的处理是优于结构化语言的,如果如让 AI 维护处理一个 dot 语言描述图,很容易出现语法错误和信息丢失,但如果处理自然语言就不太会出现这样的问题。
**(1)关系总结**
目前的 AI 的上下文还没有达到可以直接容纳一整本小说,不过我们可以通过片段文本迭代总结的方式来多次使用小的 AI 交互完成这个长上下文的总结。
与上面的文本总结不同,关系总结的侧重点是文本中的人物以及人物的关系。所以需要精切确定文本的人物信息。自然就会一个需要主要的上下文问题是:“人称代词”。所以在此 `aiforge` 的总结的迭代中添加对于人称代词的迭代修改。这样便能精确找到人物关系。
**(2)关系图转化**
这里使用 dot 图描述人物关系,是一种比较常见的文本表达图的方式。
使用此 forge 来总结一下小说《羊脂球》的人物关系:
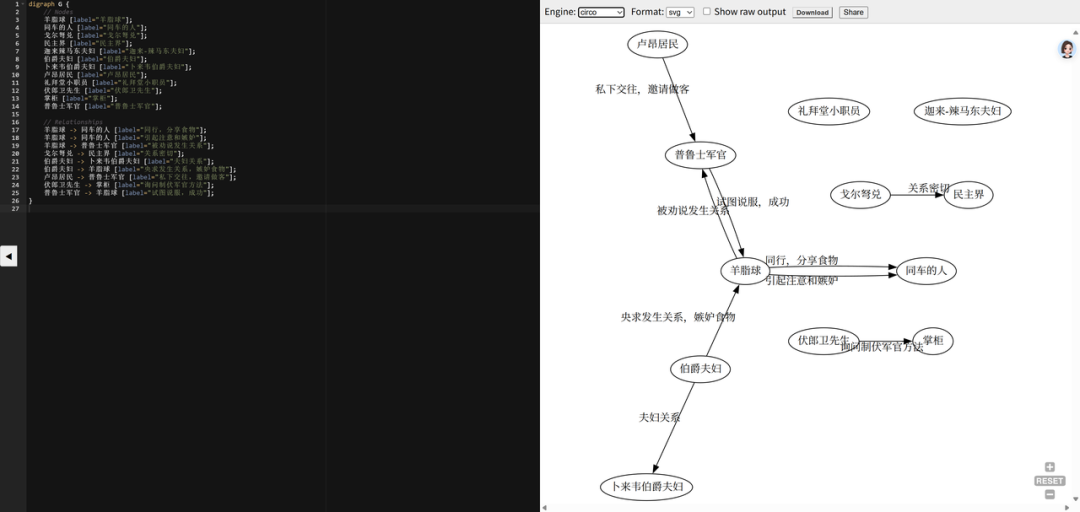
## 总结
AIForge 有一些内置通用简单 forge,可以证明其使用价值,而带入网络安全领域,不妨有更多使用场景,例如:
- 分析超大规模日志
AI 可借助外部存储系统动态加载、分块处理海量数据,通过记忆关键上下文(如跨时间段的攻击特征、异常模式关联性)实现全局推理,精准识别隐蔽的 APT 攻击链或低频威胁。
- 大流量数据清洗场景
AI 可结合外源性记忆库持续追踪数据流状态,记忆历史规则与噪声模式,过滤无效流量并修复结构化错误。
类似的场景还有很多,感兴趣的读者不妨自己编写 `aiforge` 尝试。
---
> 本文首发于 Yak Project 公众号,[阅读原文](https://mp.weixin.qq.com/s/8XapWGqjHKVyU1im_zTRJA)。